Loading
![]()
![]()
Scientists today rely on software tools for most aspects of their investigations including data collection, storage, processing, analysis, and simulation. Significant effort and intellectual capacity is often required to develop modeling tools or software. In the process of using and developing software, scientist-developers write publications about the algorithm or about scientific results based on the algorithm. However, the code itself along with any modifications made by a researcher, the “as-built blueprint” of the experiment, is often not preserved or adequately described. Thus, code becomes lost to the community. Research results cannot be verified and code cannot be reused resulting in wasted effort in its duplication. Citing code is the first step towards addressing both the issues of crediting developers’ effort in its creation and experimental reproducibility.
A frequently mentioned barrier to citing codes is the lack of knowledge - “how to”. Both developers and users require training and guidelines for proper attribution. At a minimum, there is general agreement that a code should be cited by name, version number, released date, accessed date, and that codes should be given a unique identifier. Clear and descriptive citation parameters will allow code developers and publishing agencies to receive the credit they deserve. In the era of large open source projects, the former, “who should be cited” and “what constitutes a citable unit of code” is an ongoing discussion in the community.
As part of CIG software best practices, developers are required to provide a citable publication for users of the code to refer to and cite as appropriate. Most frequently these are peer-reviewed scientific publications describing the methods on which the code is based. Less frequently, developers are able to provide a publication about the code itself (see side bar). Based on the information provided, we propose the following attribution format for the community.
An example is provided using two codes from our repository. In the example, we chose to:
We expect to update the code reference as consensus builds on how to acknowledge contributions to large codes over time.
When this format is fully implemented, the user will select a version number and code variant if applicable. Attribution information suitable for use in the main text, acknowledgement, and reference section of the manuscript citing the code will then display in plain text with an option to download. The user will have the option of specifying information specific to the code used, or can edit the placeholders as indicated. This metadata is defined here.
The proposed format is a first step in (1) promoting recognition for the significant contribution that our community makes to the advancement of science, and (2) enhancing the discoverability of scientific codes, an important factor in the ability to reproduce computational scientific research. By providing the information in an easily accessible form, we hope to encourage and systematize the practice of citing and attributing software more widely in the community.
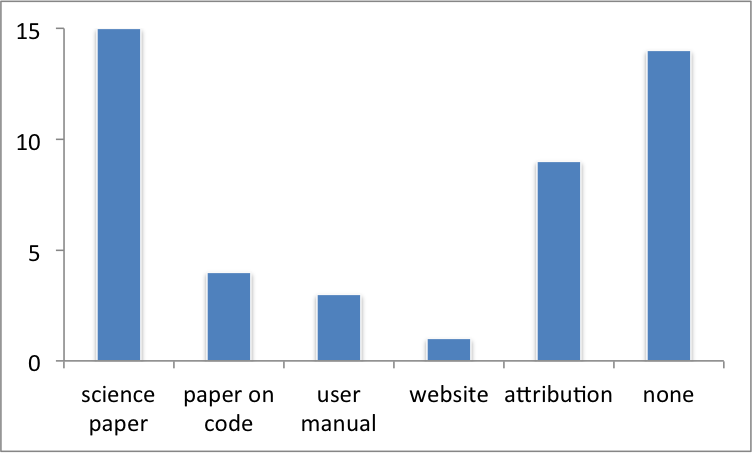
CIG developers most frequently request users to cite a science paper to attribute code usage. Requests to cite papers describing the code, paper on the code, and/or its user manual are less common. Developers may request additional attribution and/or include a url to a website. A large number have no, none, attribution information.
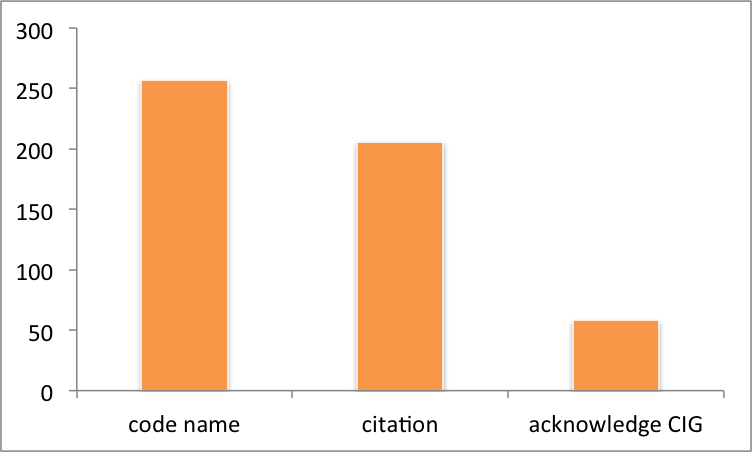
Of the 308 papers in this study, a CIG code was frequently named, code name, along with a citation. Acknowledgements to CIG, acknowledge CIG, for making the code available or NSF as the funding agency were lacking.
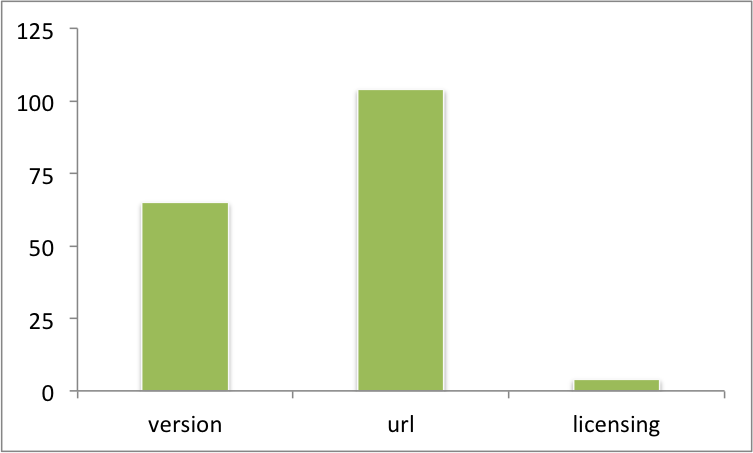
In total, software was mentioned 500 times by name. However, users frequently did not include information on the version number, a url to find the code, or information about the code license.