Loading
![]()
![]()
SoftWare Heritage’s (SWH) mission is to build the universal archive of all available software source code, preserve the precious knowledge it contains, and make it widely accessible [Di Cosmo and Zacchiroli, 2017]. With this mission in mind, it now collects, preserves and shares source code, which is accessible on the browsable archive. Figure 1 shows the most recent capture of the archive’s size.
Started over 5 years ago by Inria with support from UNESCO, Software Heritage is a non-profit initiative supported by a growing number of research institutions, industry players, and governmental bodies. SWH has a dedicated team who make sure that the infrastructure is running and capable of responding to multiple stakeholders in a variety of situations. All the code developed for SWH is released under a Free and Open Source Software (FOSS) license.
Archiving all the source code is a daunting task and there are different mechanisms put in place to ensure the preservation of source code from different types of origins. Archiving a repository from a forge isn’t the same action as archiving source code from a package manager. It becomes even harder when you realize that version control systems have evolved a lot over the last decades. In Figure 2, you can find the evolution of version control, starting with simple tools that could only operate on a local machine, like RCS, then moving to systems that relied on a central server to allow concurrent modifications to a large software project, like CVS or Subversion, and finally to Distributed Version Control Systems (DVCS) that enabled fully distributed software development, without relying on any central server (e.g Git). The SWH archive harvests source code from different sources and converts all the source code into a single and universal data structure which is an enormous Merkle DAG [Merkle, 1987].
To understand a little better how the process works, you can find in Figure 3, the listing and loading tasks:
listing
gathering all the source code urls it can find.
loading
importing or updating a source code entry, which technically means inserting blob objects (files) in the object storage, and inserting nodes and edges in the SWH archive’s graph.
When loading the source code artifacts, SWH computes and exposes the SWHID intrinsic identifier for each artifact
As shown in the Figure 4, the core of a SWHID identifier is made up by a prefix, swh (registered with IANA), a schema version, a tag to identify the type of the artifact it denotes (snapshot, release, revision, directory or content), and the cryptographic hash of the corresponding object, computed like for Merkle trees. It can also contain a set of qualifiers that provide the context of the artifact. Given a software artifact, everybody can compute the corresponding SWHID using a standard cryptographic algorithm, and can verify that it has not been modified.
It might take some time to get to every repository in the world, especially if these repositories keep on changing several times a day. This is why the “Save Code Now” service is provided, to give the possibility to notify SWH with a save request.
If you have a code repository, first check the archive by searching on the web platform.
If it is already archived, you can take a new snapshot by clicking on the camera icon on the right saying “save again”. Here an example with the ASPECT project, where you can find the latest visit, or all the visits.
If you can’t locate your source code, you can go ahead and click on “Save code now”, which is available on the menu on the left side of the archive’s platform. For interested developers, there is also a dedicated API endpoint.
By doing so, a priority task will be created for your repository and the content will be archived, after a moderator’s validation, usually a few hours later.
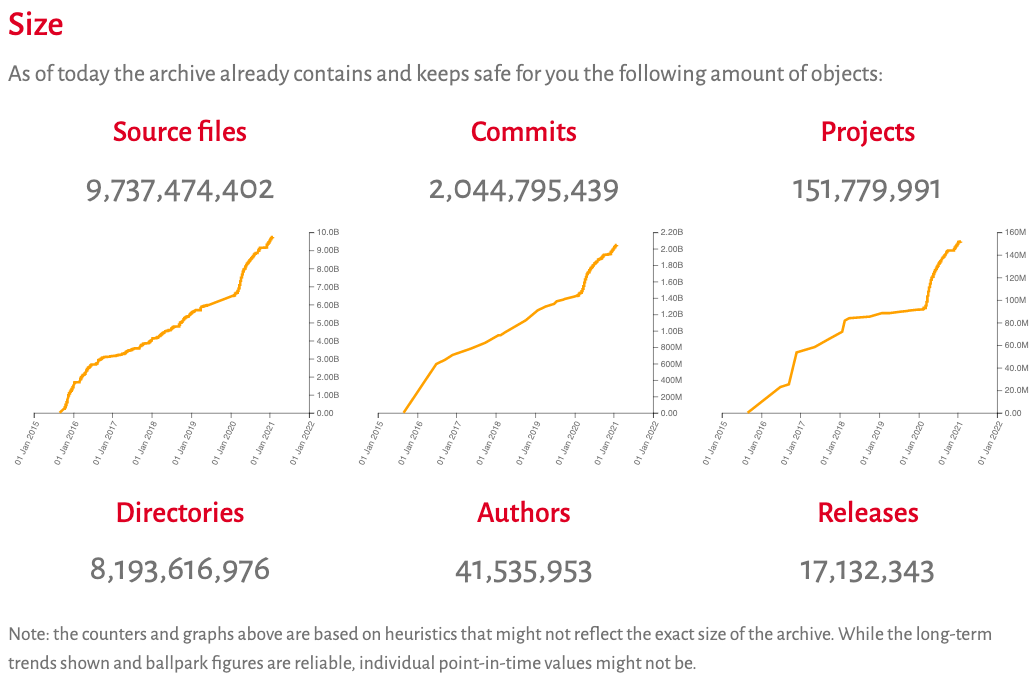
Figure 1. The Software Heritage archive size on January 29th, 2021, captured from https://archive.softwareheritage.org/
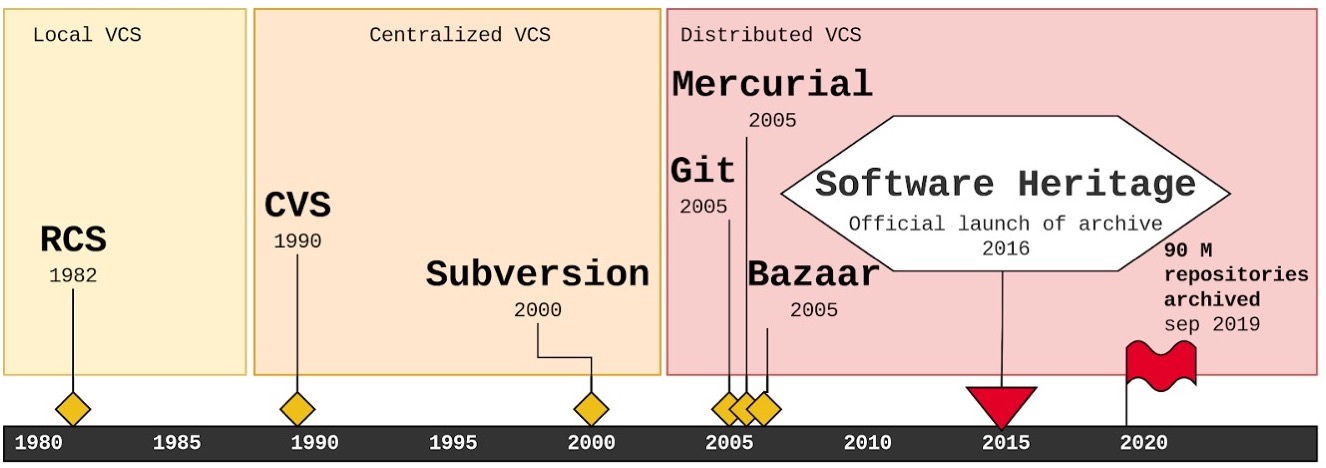
Figure 2. The evolution of software source code version control systems. This figure was taken from: Research Data Alliance/FORCE11 Software Source Code Identification WG et al. (2020). Use cases and identifier schemes for persistent software source code identification (V1.1). Research Data Alliance. https://doi.org/10.15497/RDA00053
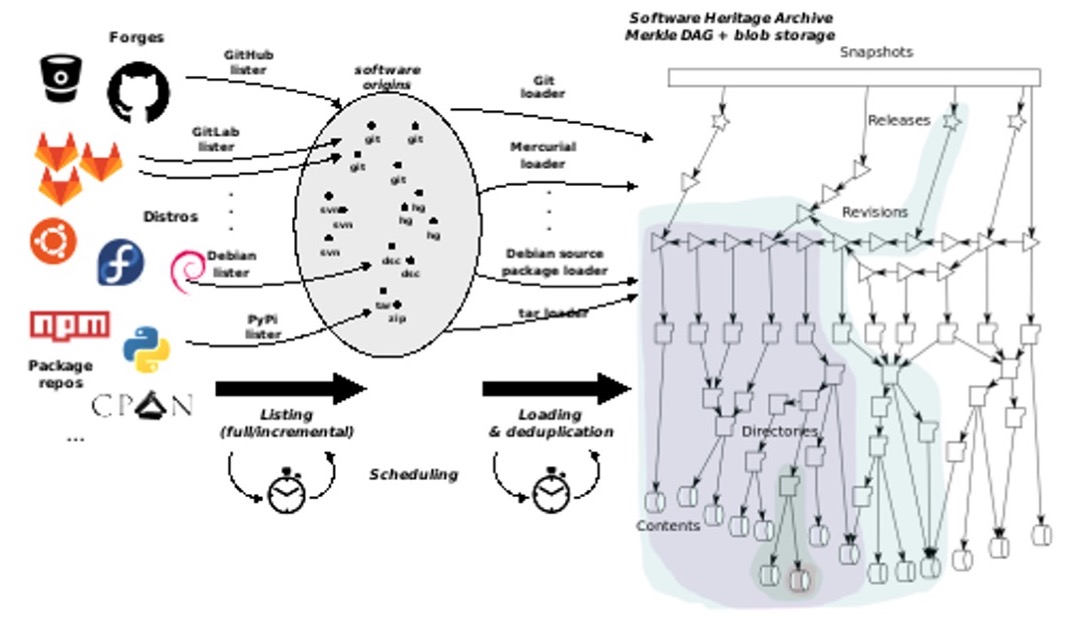
Figure 3. Architecture of the Software Heritage crawler [Di Cosmo, 2020].
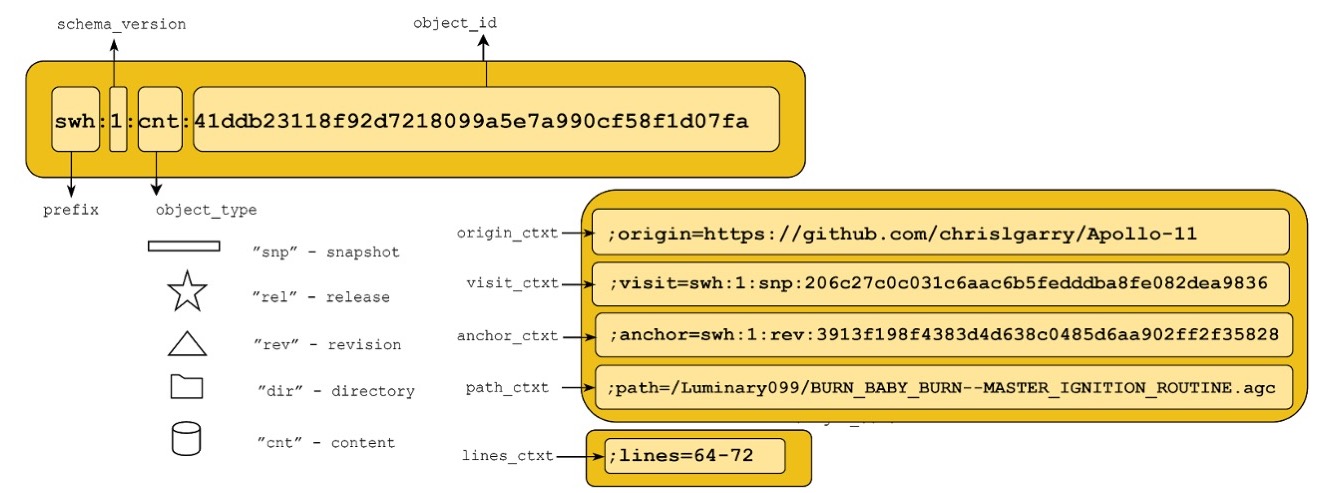
Figure 4. The SWHID identifier scheme [Di Cosmo et al., 2020].
Once your source code has been archived, there are many ways to reference it. Here are a few examples of possible references:
adding a link to the full repository archived in Software Heritage, by choosing a snapshot. Last visit on January 11 2021 of the ASPECT project can be referenced with the following SWHID containing all branches and all releases:
swh:1:snp:75cdaf5164207cb3d00f07a3da10a0250b29d03b;
origin=https://github.com/geodynamics/aspect
adding a link to a precise version of the software project, by choosing a release or a revision (commit). ASPECT’s V2.2.0 can be referenced with the SWHID below:
adding a link to a precise version of a source code file, by choosing a file:
Adding a link to a code fragment which can be a specific algorithm, by choosing the lines on the file and keeping the qualifier “lines of code” in the SWHID. The link below references the minimal and maximal temperature functions on that part of the boundary on which Dirichlet conditions are posed.
I invite you also to check the detailed tutorial on how to cite software using BibLateX, which shows how to use the biblatex-software package available from CTAN (you may have it already installed on your machine if you use TexLive) and how to add the SWHID as a reference in a citation. For more information on how to archive and reference your code, check the SWH guidelines or the detailed ICMS 2020 article and the associated ICMS online video.
The Software Heritage project is supported by UNESCO and many international partners and sponsors such as Microsoft, Huawei, MESRI, Intel, Société Générale, CNRS, OIN, Sorbonne Université, CAST, DINSIC, Google, GitHub, Università di Pisa, VMware, DANS (institution of the Royal Academy of Arts and Sciences of the Netherlands), the University of Bologna and FOSSID.
Contributed by:
Morane Gruenpeter
Inria research center
Software Heritage team
References
Di Cosmo, Roberto (2020). Archiving and Referencing Source Code with Software Heritage In proceedings. ICMS, pp. 362–373, Springer, 2020, ISBN: 978-3-030-52200-1. https://dx.doi.org/10.1007/978-3-030-52200-1_36
Di Cosmo, Roberto, Gruenpeter, Morane, and Zacchiroli, Stefano (2020). Referencing Source Code Artifacts: a Separate Concern in Software Citation Journal Article Computing in Science & Engineering, ISSN: 1521-9615. https://dx.doi.org/10.1109/MCSE.2019.2963148 https://hal.archives-ouvertes.fr/hal-02446202
Di Cosmo, Robert and Zacchiroli, Stefano (2017). Software Heritage: Why and How to Preserve Software Source Code. In Proceedings of the 14th International Conference on Digital Preservation, iPRES 2017. https://hal.archives-ouvertes.fr/hal-01590958
Merkle, Ralph C. (1987). A Digital Signature Based on a Conventional Encryption Function. In Advances in Cryptology – CRYPTO ’87, A Conference on the Theory and Applications of Cryptographic Techniques, Santa Barbara, California, USA, August 16-20, 1987, Proceedings (Lecture Notes in Computer Science), Carl Pomerance (Ed.), Vol. 293. Springer, 369–378. https://doi.org/10.1007/3-540-48184-2